A ideia inicial desse tutorial foi de pegar os dados que estão disponíveis no site cnpj.info/lista e montar uma base de dados local para utilizá-los como massa de testes para um tutorial futuro (sobre a criação de uma extensão para o chrome). Para instalar o projeto siga os passos abaixo
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
O segredo para o scraping está no arquivo app/Http/Controllers/GoutteController.php, método doWebScraping, que é acessado pela url http://127.0.0.1:8000/web-scraping
O próximo passo, é, informar nessa página os seletores que queremos extrair da página. É bem simples, o processo consiste em abrir o dev-tools, inspecionar, e copiar o seletor. Subi um video (abaixo) que mostra o processo.
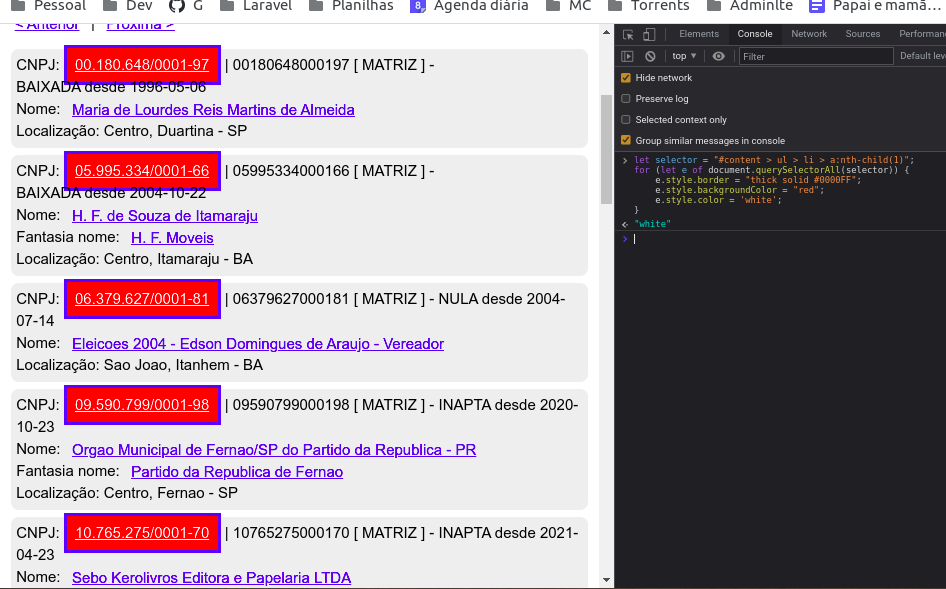
Um detalhe que temos que ficar atentos, é que o dev tools nos retorna, geralmente, apenas um elemento … como por exemplo aqui:
#content > ul > li:nth-child(2) > a:nth-child(1) (Esses seletores significam que estão pegando o segundo filho do li, e o primeiro filho do a, apenas isso. Então no nosso caso, retire essas informações de filhos, ficando assim
#content > ul > li > a:nth-child(1)
Para confirmar se esse seletor funcionará, cole o seguinte trecho na aba console do dev tools
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Caso os seletores fiquem da seguinte forma, significa que você pegou o seletor correto.
Caso esteja correto, agora é só acertar nosso controller, para fazer download e salvar nossos dados no banco de dados (sqlite, incluso no repo)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters